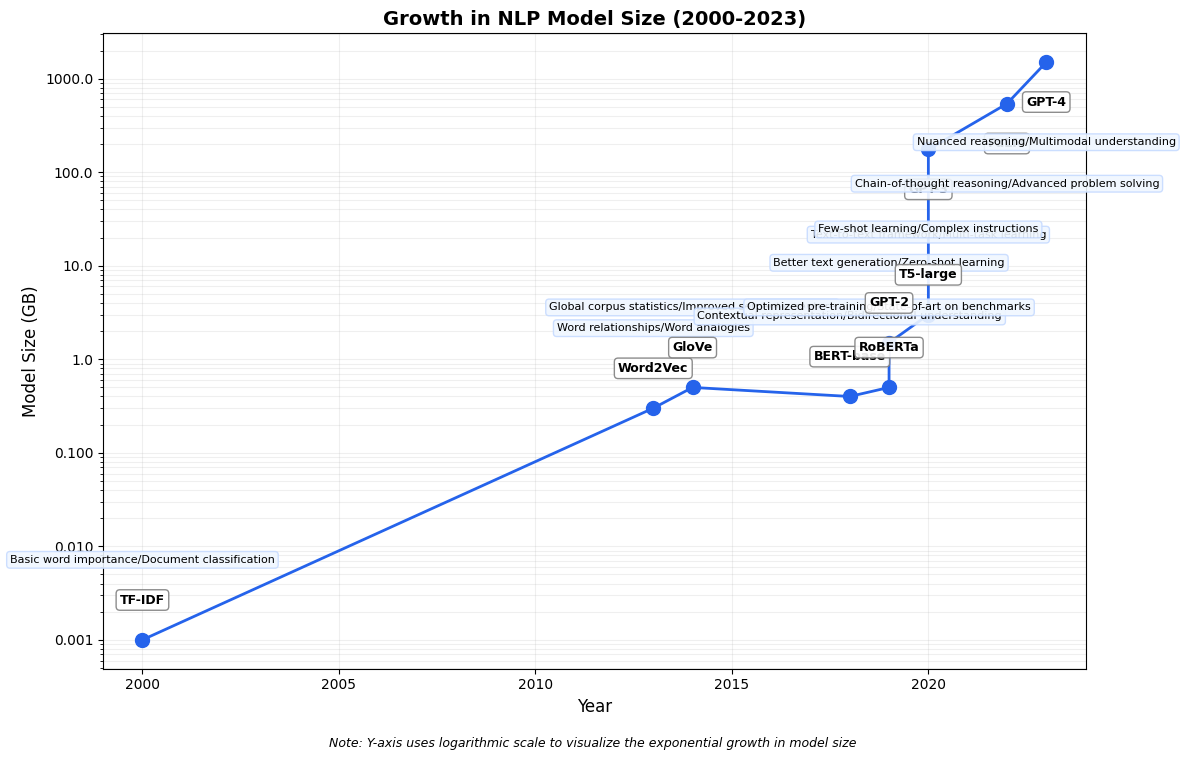
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter
# Create DataFrame with model data
data = {
'name': ['TF-IDF', 'Word2Vec', 'GloVe', 'BERT-base', 'RoBERTa', 'GPT-2',
'T5-large', 'GPT-3', 'PaLM', 'GPT-4'],
'year': [2000, 2013, 2014, 2018, 2019, 2019, 2020, 2020, 2022, 2023],
'size': [0.001, 0.3, 0.5, 0.4, 0.5, 1.5, 3, 175, 540, 1500], # Size in GB
'capability': [
'Basic word importance/Document classification',
'Word relationships/Word analogies',
'Global corpus statistics/Improved semantic capture',
'Contextual representation/Bidirectional understanding',
'Optimized pre-training/State-of-art on benchmarks',
'Better text generation/Zero-shot learning',
'Text-to-text framework/Multi-task learning',
'Few-shot learning/Complex instructions',
'Chain-of-thought reasoning/Advanced problem solving',
'Nuanced reasoning/Multimodal understanding'
]
}
df = pd.DataFrame(data)
# Sort by year for proper timeline
df = df.sort_values(by=['year', 'size'])
# Create figure and axis
plt.figure(figsize=(12, 8))
ax = plt.subplot(111)
# Plot with log scale for y-axis to handle the dramatic size differences
ax.semilogy(df['year'], df['size'], marker='o', markersize=10,
linewidth=2, color='#2563eb')
# Format y-axis to show values nicely
def size_formatter(x, pos):
if x < 1:
return f"{x:.3f}"
else:
return f"{int(x) if x == int(x) else x:.1f}"
ax.yaxis.set_major_formatter(FuncFormatter(size_formatter))
# Add annotations for each model
for i, row in df.iterrows():
# Determine annotation placement (above or below point based on position)
if row['size'] > 10:
y_offset = -1.2 # Place below for large models
va = 'top'
else:
y_offset = 1.2 # Place above for small models
va = 'bottom'
# Add model name
ax.annotate(
f"{row['name']}",
xy=(row['year'], row['size']),
xytext=(0, 20 * y_offset),
textcoords="offset points",
ha='center',
va=va,
fontweight='bold',
fontsize=9,
bbox=dict(boxstyle="round,pad=0.3", fc="white", ec="gray", alpha=0.9)
)
# Add capability text in smaller font
ax.annotate(
f"{row['capability']}",
xy=(row['year'], row['size']),
xytext=(0, 45 * y_offset),
textcoords="offset points",
ha='center',
va=va,
fontsize=8,
bbox=dict(boxstyle="round,pad=0.3", fc="#f0f7ff", ec="#c7dbff", alpha=0.9),
wrap=True
)
# Add labels and title
plt.xlabel('Year', fontsize=12)
plt.ylabel('Model Size (GB)', fontsize=12)
plt.title('Growth in NLP Model Size (2000-2023)', fontsize=14, fontweight='bold')
# Add grid for better readability (especially with log scale)
plt.grid(True, which="both", ls="-", alpha=0.2)
# Adjust the x-axis to give some padding
x_min, x_max = df['year'].min() - 1, df['year'].max() + 1
plt.xlim(x_min, x_max)
# Add a note about log scale
plt.figtext(0.5, 0.01,
"Note: Y-axis uses logarithmic scale to visualize the exponential growth in model size",
ha="center", fontsize=9, style='italic')
# Layout adjustment to make space for annotations
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
# Save the figure
plt.savefig('nlp_model_size_growth.png', dpi=300, bbox_inches='tight')
# Show the plot
plt.show()
# Display the data as a table
print("\nNLP Model Size and Capability Data:")
print(df[['name', 'year', 'size', 'capability']].to_string(index=False))